Artificial Analysis Coding Agent Benchmarks
Artificial Analysis added coding agent benchmarks. It shows the influence of harnesses - significant - and the work Cursor has done with theirs.
Artificial Analysis' Coding Agent Benchmarks is a good addition to their benchmarks. It shows the influence of harnesses, which is significant (e.g. Opus 4.7 medium in different harnesses below). It also shows the work Cursor have done with theirs!
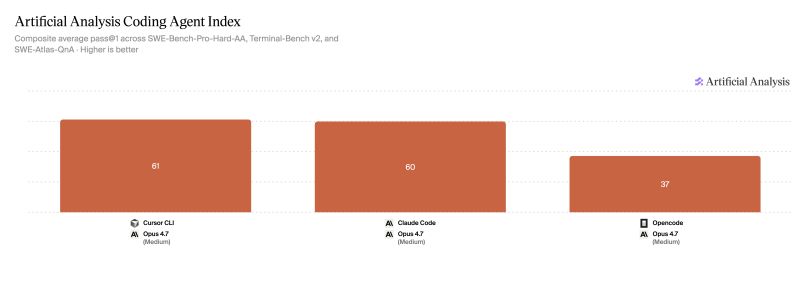
I wish there was a bit more variety, however:
- Additional harnesses, e.g. Pi
- Additional models: e.g., MiMo, Grok
But, great start!
Olivier Reuland